Redis란?
고성능 Key-Value 구조의 저장소로, 비정형 데이터를 저장 및 관리하기 위한 오픈 소스 기반의 NoSQL DB
In-Memory 데이터 구조를 사용해 웹 서버의 부담을 줄이고 고속으로 데이터를 제공하는 데 탁월하다
Redis의 주요 특징
1. In-Memory 데이터베이스
Redis는 데이터를 RAM에 저장하여 디스크 기반 데이터베이스보다 매우 빠른 속도를 자랑함
RAM을 사용함으로써 디스크 I/O가 발생하지 않아 데이터 처리 속도가 대폭 향상됨
- 장점: 빠른 데이터 저장 및 조회
- 단점: RAM 용량 초과 시 데이터 유실 가능 (휘발성)
→ 휘발성 문제 해결: 백업 기능(AOF, RDB)을 제공하여 데이터 유실 위험을 방지
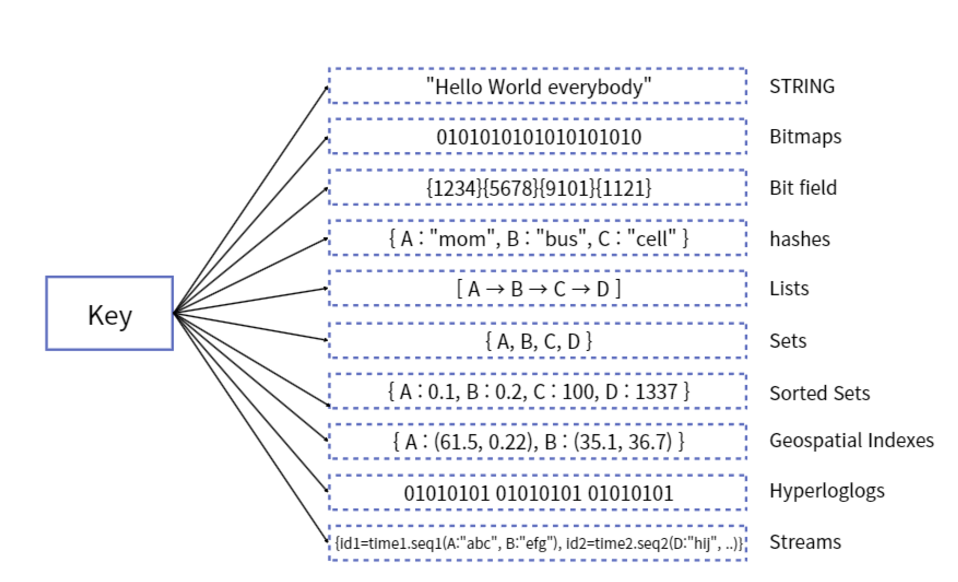
2. Redis의 데이터 타입
Redis는 다양한 데이터 타입을 지원하며, 이를 활용하면 복잡한 데이터 작업을 간소화할 수 있다
- String: 일반적인 Key-Value 형태
- Hash: Key-Value 형태를 테이블 형식으로 저장
- List: 순서가 있는 값들의 목록
- Set: 중복 없는 값들의 집합
- Sorted Set: 정렬 가능한 집합
eg) Sorted-Set을 사용하면 데이터를 정렬하는 로직을 단순화하고 처리 속도를 높일 수 있음
3. Redis의 백업과 복구
Redis는 데이터를 디스크에 저장할 수 있는 두 가지 주요 방식을 제공
AOF(Append Only File)
개념
AOF는 Redis의 모든 Write/Update 연산을 파일에 순차적으로 기록하는 방식
Redis 서버가 중단되더라도, AOF 로그를 재실행하여 데이터 상태를 복구할 수 있다
동작 방식
- Redis에 Write/Update 연산 발생
- 해당 연산을 AOF 파일에 순서대로 기록
- Redis 서버 재시작 시 AOF 파일의 명령어를 순차적으로 실행하여 복구
장점
- 데이터 복구 가능성이 매우 높음 (모든 연산을 기록)
- Write/Update 중심의 데이터베이스에서 적합
- 사람이 읽을 수 있는 명령어 형태로 저장되어 디버깅이 용이
단점
- 파일 크기가 커질 수 있음 → 주기적인 파일 압축(Rewrite) 필요
- 디스크 I/O 부담이 큼 (많은 Write 작업 발생 시)
추가 옵션
- fsync 옵션: 데이터 기록 주기를 조정해 성능과 안정성을 조율
- always: 매 Write마다 디스크에 기록 (가장 안전, 성능 낮음)
- everysec: 1초마다 기록 (기본값, 안정성과 성능 균형)
- no: Redis가 디스크 기록을 관리하지 않음 (가장 빠름, 안전성 낮음)
RDB(Snapshotting)
개념
RDB는 Redis 데이터를 특정 시점(Snapshot)에 전체적으로 저장하는 방식
정해진 간격으로 메모리에 있는 모든 데이터를 디스크에 저장하여 백업본을 생성한다
동작 방식
- 주기적 또는 특정 조건에서 Redis가 전체 데이터를 Snapshot 형태로 디스크에 저장
- Snapshot 파일(dump.rdb) 생성
- Redis 서버 재시작 시 Snapshot 파일을 로드하여 복구
장점
- AOF보다 디스크 사용량이 적음 (스냅샷 방식)
- 빠른 복구 시간 → 대량의 데이터를 효율적으로 복구 가능
- 디스크 I/O 부하가 적음 → 고성능 애플리케이션에 적합
단점
- 스냅샷 사이의 데이터는 유실될 가능성 있음
- 예: 매 5분마다 Snapshot을 저장하는 경우, 마지막 5분간의 데이터는 복구 불가
- Write 중심 환경에서는 적합하지 않을 수 있음
사용 방법
- Redis 설정 파일에서 Snapshot 주기 설정 가능
예: save 60 10000 → 1분 동안 10,000개 이상의 키가 변경될 경우 Snapshot 생성
4. 고가용성과 확장성
Redis는 Sentinel 및 Cluster를 통해 고가용성과 확장성을 제공한다
- Sentinel: 자동 장애 복구, 모니터링, 알림 등 제공
- Cluster: 자동 파티셔닝을 통해 데이터를 여러 Redis 인스턴스에 분산
● 파티셔닝(Partitioning): 다수의 Redis 인스턴스에 데이터를 분산 저장하여 확장성을 높이고, 각 인스턴스는 자신에게 할당된 데이터만 관리
5. 싱글 스레드 구조
Redis는 기본적으로 싱글 스레드로 동작하며, 하나의 명령만 순차적으로 처리한다
- 장점: Race Condition(경쟁 상태) 문제를 방지하여 데이터 일관성 보장
- 단점: 복잡하거나 처리 시간이 긴 요청이 있으면 Redis 서버의 응답이 느려질 수 있음
Redis 사용시 주의사항
메모리 관리
Redis는 데이터를 RAM에 저장하는 In-Memory 데이터베이스이기 때문에, 사용 가능한 메모리 용량을 초과할 경우 데이터 유실이나 성능 저하가 발생할 수 있다
해결 방법
- 메모리 정책 설정: Redis는 메모리 초과 시 데이터를 삭제하는 정책을 지원한다.
- 설정 가능한 maxmemory-policy 값:
- noeviction: 메모리 초과 시 새 데이터를 추가하지 않음 (기본값)
- allkeys-lru: 가장 오래 사용되지 않은 키부터 삭제
- volatile-lru: 만료 설정이 있는 키 중 가장 오래 사용되지 않은 키부터 삭제
- allkeys-random: 임의의 키 삭제
- volatile-random: 만료 설정이 있는 키 중 임의의 키 삭제
- volatile-ttl: 만료가 가장 가까운 키 삭제
- 메모리 사용량 모니터링:
- 주기적으로 Redis 메모리 사용량을 확인 (INFO memory 명령 사용)
- maxmemory 설정으로 Redis가 사용할 메모리 한도를 제한
- 데이터 크기 관리:
- TTL(Time-To-Live)을 설정하여 필요 없는 데이터가 Redis에 오래 남아 있지 않도록 관리
- Redis에 대량의 데이터를 저장하기보다는, 캐싱 목적으로 사용
데이터 복구
Redis는 기본적으로 In-Memory 데이터베이스이므로, 시스템 장애나 전원 차단 시 데이터가 유실될 수 있다
해결 방법
- 백업 설정:
- AOF(Append Only File)와 RDB(Snapshotting)를 적절히 설정하여 데이터 복구를 대비
- 주기적으로 백업 파일을 외부 저장소에 보관
- 복구 테스트:
- 장애 상황을 가정한 복구 프로세스를 사전에 테스트하여 복구 시간을 단축
명령어의 시간 복잡도
Redis 명령어의 시간 복잡도를 고려하지 않고 대량의 데이터를 처리하는 명령을 실행하면 서버 성능 저하나 장애를 유발할 수 있다
해결 방법
- 시간 복잡도 확인:
- 데이터 크기에 따라 처리 시간이 증가하는 명령어는 주의 (O(N) 이상의 명령어)
- 예: KEYS, SORT, LRANGE(큰 범위) 등
- 대체 명령어 사용 추천:
- KEYS 대신 SCAN(Cursor 기반 점진적 조회)
- 긴 LRANGE 대신 데이터 크기 제한 및 페이징 사용
- 데이터 크기에 따라 처리 시간이 증가하는 명령어는 주의 (O(N) 이상의 명령어)
- 배치 처리:
- 대량 데이터를 처리할 경우 파이프라이닝(Pipelining)을 사용해 성능 최적화
싱글 스레드 특성
Redis는 싱글 스레드로 동작하므로, 하나의 명령이 오래 걸리면 다른 명령의 처리가 지연될 수 있다
해결 방법
- 처리 시간이 긴 작업 최소화:
- 긴 명령어를 실행할 때는 데이터를 나누어 처리하거나 백그라운드로 실행
- 클러스터링:
- Redis Cluster를 구성해 작업을 분산 처리
보안
Redis는 기본적으로 인증과 네트워크 보안을 제공하지 않으므로, 외부 공격에 취약할 수 있다
해결 방법
- 인증 설정:
- Redis 설정 파일에서 비밀번호(requirepass)를 설정
- 네트워크 보안:
- Redis를 외부 네트워크에 노출하지 않고, 방화벽이나 VPN을 통해 접근 제어
- 필요 시 TLS를 활성화하여 암호화된 통신 사용
- IP 제한:
- 설정 파일에서 bind 옵션으로 특정 IP에서만 Redis에 접근하도록 설정
메모리 단편화
크고 작은 데이터를 할당하고 해제하는 과정에서 메모리 단편화가 발생해 성능이 저하될 수 있다
해결 방법
- Redis 메모리 관리 도구(mem_fragmentation_ratio)로 단편화 수준을 주기적으로 점검
- Redis 설정에서 activedefrag 옵션을 활성화해 단편화를 자동으로 해소
클러스터 및 복제 구성 시 주의점
Redis Cluster와 복제를 잘못 구성하면 데이터 불일치, 성능 저하, 장애 복구 실패가 발생할 수 있습니다.
해결 방법
- Redis Cluster:
- 키 분배 방식(Hash Slot)을 이해하고, 동일한 키 패턴을 사용해 데이터 분산
- 클러스터 환경에서 마스터-슬레이브 구조를 활용해 읽기 작업을 분산
- Redis Sentinel:
- Sentinel을 구성하여 마스터 장애 시 자동 복구 및 알림 설정
로그 및 모니터링
Redis 서버에서 발생하는 문제를 조기에 감지하지 못하면 심각한 장애로 이어질 수 있다
해결 방법
- 모니터링 도구 사용:
- Redis의 상태를 실시간으로 확인할 수 있는 도구 사용:
- Grafana, Prometheus 등의 모니터링 툴과 통합
- 주요 모니터링 지표:
- 메모리 사용량(used_memory, maxmemory)
- 명령 실행 속도 및 처리량(instantaneous_ops_per_sec)
- 연결 상태(connected_clients)
- Redis의 상태를 실시간으로 확인할 수 있는 도구 사용:
- 로그 관리:
- Redis 로그 레벨을 notice로 설정하여 주요 이벤트 기록
- 장애 발생 시 로그를 분석하여 원인 파악
'CS' 카테고리의 다른 글
| [CS] WebSocket 채팅 기능 비정상 종료 방지 및 연결 유지 방법 (1) | 2024.10.29 |
|---|---|
| [CS] JPA N+1 문제 (0) | 2024.10.24 |
| [CS] 교차 출처 리소스 공유 (Cross-Origin Resource Sharing, CORS) (5) | 2024.10.16 |
| [CS] 해시 알고리즘(Hash Algorithm) (0) | 2024.10.08 |